Hamburger anyone?
Under the idea of learning something new every day, I stumbled upon a nice article depicting the flaws of the hamburger menu.
And I learned a thing or two. So instead of rehashing the article here, I invite you to click the link above, leave my website and have a good read.
node.js vs Java nashorn

Why did I test it?
In my current Java project, I make some use of JavaScript. Performances were quite horrendous with Rhino in java 6 and 7, but in Java 8 there is a brand new JavaScript runtime: Nashorn.
Its principal feature is that it's much faster than Rhino. At last, we're going to be able to execute some serious javascript on the server side. Given the richness of the node.js ecosystem, that's a whole new bunch of tools at our disposal. But will they run fast, or fast enough?
First, why not just run those scripts with node?
There are several things in there. When I do Java, I know that what I do is highly portable. Much more so than in any other language, node.js included. So dragging a dependency on node.js annoy me. Also, it's much easier to communicate with nashorn (give it inputs, get outputs back or even callbacks) than with an external process. But most of all, the stability of the whole ecosystem kind of scares me. npm is broken every other day and more often than not, upgrading anything leads to a whole bunch of problems. The simple fact that this whole thing is not even packaged for Ubuntu leaves me wondering.
What did I test?
So, for a practical test, I wanted to minify javascript libs on the fly. So I took a typical Javascript payload from my website and applied UglifyJS to it. The initial payload is the blind concatenation of all the JS files at my disposal in my repo. That's about 62kb of JavaScript. This is real JavaScript used in a real world application, not some dummy routine.
First of all, the compression result. I have a slightly different script to run on node.js and on Java, but they all give an output of 28909 bytes out of 62498. I used the same options for both: do it all, compress as hell.
Notes: I'm running this on an Ubuntu 14.04LTS with a Q6600, an old quad-core from Intel not hyper-threaded. I've tested Java 1.7.0_11, 1.8.0_05 and 1.8.0_45 (with the optimistic type system enabled in nashorn)
The test
The results of the first run (that's after uglifyjs has been loaded):
- node.js: 910ms
- Java 8u05: 22s
- Java 8u45: 28s
- Java 7: 19s
So, Java 8 is slower than Java 7. Node crushes them pretty hard - and that's quite an understatement. Note that the newer the version of Java, the worse it is. I surely did not expect that. I don't know much about V8 (node js engine), but I know a few things about Java. HotSpot takes its time to optimize the code it runs. Let's do a for loop with 10 iterations and see how much time it takes at the 10th iteration:
- node.js: 600ms - one core used
- Java 8u05: 3.6s - three cores used - about 10.8s cpu time
- Java 8u45: 3s - three cores used - about 12s cpu time
- Java 7: 17s - one core used
Now, this is more interesting. Java 8 is clearly ahead, but still about 6 times slower than node. Java8u45 is a bit ahead on that one. Java7 is still dreadful, but that was expected.
A last note on the cores used. I noticed it during this test because it runs for longer than the first one. Both tests involving Java 7 and node.js take about 100% CPU, which means they use one core (out of my quad core). The test in Java 8 uses about 300% CPU, which means bout three cores. This is also true for the first test of course, but I didn't notice it at first.
Let's do one more test: After 100 compressions, how much time does it take?
- node.js: 560ms, one core used
- Java 8u05: 1.5s, two cores used so about 3s cpu time
- Java 8u45: 2s, three cores used so about 6s cpu time
- Java 7: 17s - one core used
Well, this isn't much of a game changer, but it show one thing: Java 8 takes its time to optimize its shit. The Java8u05 process went from 300% to 200% cpu at around iteration 55. Java8u45 went down to 200% CPU at iteration 140, getting the script done in around 1.3s but that was too late for the iteration 100 threshold.
Even after the 10th iteration, it continues to go faster. And after a while, it only takes two cores, not three. This is less bad for Java 8 than the previous one. Now Java is only 2.7 times slower than node and 5.4 times if you count CPU time.
Edit: Let's do one more test: After 1000 compressions, how much time does it take?
- node.js: 670ms, one core used
- Java 8u05: 1.3s, 1.2 core used
- Java 8u45: 1.1s, 1 core used
- Java 7: 17s - one core used
Yes, you read that correctly, node.js is going slower after 1000 iterations...
Well, the least one can say it's that Java isn't fast... to become fast. The cpu consumption went from 200% to 120% at around iteration 155. My guess is that the extra cores used were due to the optimizer. It seems to be a heck of a lot of work.
Well, now we can say that Java 8 warmed up is a bit less than 2 times slower than node. But it takes a hell of a lot of time to get there. That said, the result isn't bad at all, given all the resources Google did put in its V8 engine. Java is capable to execute JavaScript at a decent speed.
Wrap up
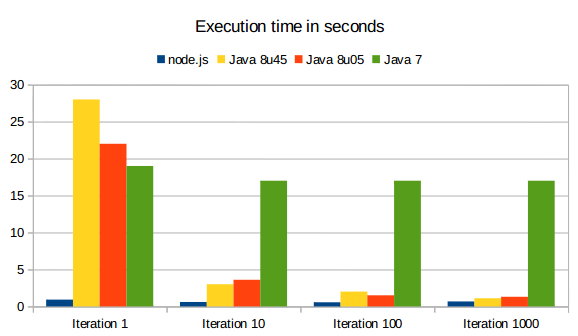
| seconds | Iteration 1 | Iteration 10 | Iteration 100 | Iteration 1000 |
|---|---|---|---|---|
| node.js | 0.910 | 0.6 | 0.56 | 0.67 |
| Java 8u05 | 22 | 3.6 | 1.5 | 1.3 |
| Java 8u45 | 28 | 3 | 2 | 1.1 |
| Java 7 | 19 | 17 | 17 | 17 |
After discarding all results above 5s (so discarding Java7 entirely) and discarding iterations above 200 (they don't seem to change anything but for node who keeps climbing a little to 670ms and then stabilizes), here are the numbers:
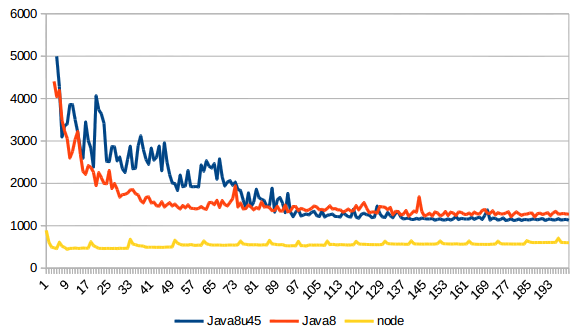
I don't know about you, but for my server, I'd rather have a curve that does down than a curve that goes up like node. It would seem as if Java8u45 is longer to warm up but gives better results when warmed up. In the end, Java is 1.6x slower than node, so it can execute its share of JavaScript on the server side. Depending on what you need, it might do the trick. It has to warm up though before being that performant.
The other thing I've learned is that if I want to minify my JavaScript on the fly, I'm going to need some sort of caching mechanism, because none of those run times gives me acceptable performance. This mitigates the 1.6x factor between Java8 and nodejs.
I've also learned that I'll need some sort of warmup at startup, not for my app, but for my JVM. I mean, the first guy getting there will have to wait 22 seconds before getting its JavaScript served? No way, thankyouverymuch.
I've tried a little playing with Java9 but it isn't really mature at this point so I won't disclose anything. Results are on par with Java 8u45. I strongly hope Oracle will pull their shit together and optimize this further.
That is unless they decide to enforce their copyrights on the Java API in which case they'll have to license this JavaScript API from Netscape. It seems only fair. Then again, they'll have to get a license for SQL from IBM, or else they'll go out of business.
Oracle, please spend less in lawyers that undermine your core business and more on engineers which will give a chance to your products. My $.02.
A final note on performance
This warmup that we have seen in the graph is a mix of the JVM warmup and Nashorn engine. But mostly, it is Nashorn. This means that if you create an engine every time you need to execute a script, you won't benefit from it. Here is the most simple way to create an engine:
Well, those pesky ScriptEngine objects created? Never discard them, or else you'll discard the entire optimizations with them.
mdadm: replacing a disk

It's the first time for me that a HDD in a raid1/5 array fails on me. I guess there has to be a first time for everything.
Anyways, I have a 6-2TB disk raid5 array for a total capacity of 10TB. I've had that array for now about 5 years. It's filled with 2TB hard disk drives and has been working pretty smoothly for me. 450MB/s read throughput is how I like it. It's even faster than my GB network, so this has never been the culprit in any of my operations.
For the record, I used the tool idle3-tools from cbothamy to reset my sleep time to something worthy. I have WDC green drives (see the picture, which is actually the drive that failed), and their default settings are really nuts. Really nuts.
Also for the record, my boot drive is a single old Maxtor 320GB drive and has nothing to do with mdadm. So if you have issues with booting onto your mdadm array, look no further. This page is not for you.
Now, I've had a failure this morning and I've had to change one of the drive. I have a "regular" box (See here for pics and french text) so there was no hot-swapping involved. But just a 5 minute downtime was good enough for me.
How did I find out about the faulty drive? Well, I have an "Error" section in my conky configuration and it outputs the diff of the regular /proc/mdstat with the initial one. Just logging into my desktop alerted me right away with a big red section that is usually empty right on my desktop. This is important, because if you don't monitor your raid array, it'll fail eventually on more than one drive and you'll lose everything. Note that from time to time, a red section appears in my conky as mdadm runs a routine check of the raid array.
Now, how do you get down to it. First, I needed to figure out which drive in my raid array was faulty. Here was the result of my mdstat file:
First a little explanation. The [UUUUU_] indicates the number of good disks (U) vs. the number of faulty disks (_). Similarly, the 6/5 indicates the number of total disks in the array (6) vs. the number of working disks (5). At last, the (F) next to sdf1 indicates the partifion that isn't available anymore.
Well... clearly one of the drives has made it to heaven, and it was /dev/sdf. Or has it? Could it just be a software glitch? In doubt, I reboot the server to see if things will get better. After a fight against the BIOS to make it boot with a faulty drive, I notice the same thing. I kinda hoped it would be a defect in the disk driver. Alas...
Well, the HDD seems to be dead. Let's remove it.
First, let's remove the drive from the array in mdadm:
This is done and mdadm is now aware that there is no disk /dev/sdf1 anymore. Next, I need to open the box and locate the good drive. Now... which one is it? I have 6 WDC green in my box... Let's list all the drives with their serial number:
Well... The faulty drive doesn't show its serial number anymore. The good news is that I have the serial numbers of the other drives and I'll be able to locate the one that I don't have.
I just opened the box, looked for a drive with a serial number not on my list, swapped it with a new one and put everything back together. Note that I did take care of making sure I did not swap SATA plugs. I wanted to make sure the new drive was on the same SATA plug the faulty one was on. I don't know if it matters.
After booting up, my raid array was in the same state as before shutting down. First, I had to partition the drive the same way the others were partitioned. I ran (as root):
Now, don't get mixed up with your drives. This will effectively erase the partition table of your drive, copying from /dev/sde to /dev/sdf. Depending on your setup, you can lose everything on the target drive. Here it was /dev/sdf, my newly installed drive.
The last thing I needed was to add the new drive to the array:
And that's all... almost. Now mdadm will rebuild the new drive with the data it should contain. It took about 500 minutes for me, a little more than 8 hours, so be patient. This will take time.
A few hours later, and my raid array is slowly recovering from the disaster:
As you can see, I still have 102.6 minutes left.
When everything was done:
I have to say I'm surprised at how smooth everything went. I haven't lost a byte and I still have a spare drive, although I'll need a few others if/when this happens again.
My first experience with mdadm was kind of a disaster, but it was because I used it as my / partition. Debugging it in busybox wasn't a lot of fun. But this time around, everything went smooth.
References
Bootstraping my mdadm CLI skills: http://tldp.org/HOWTO/Software-RAID-HOWTO-6.html Where is that damn disk again? http://unix.stackexchange.com/questions/121757/harddisk-serial-number-from-terminal mdadm recovery, removing, adding a drive. https://www.howtoforge.com/replacing_hard_disks_in_a_raid1_arrayEmbrace boredom

I know, I'm a programmer. And as such, everyday or so of my life for the last 20 years I've written code. Most of it has been thrown away by now, but a good chunk is still alive and kicking. And what happens to this code now? Well, from time to time someone take a look at it and try to think "how am I going to make this code do what I want it to be doing". And if this person finds an answer quickly, the code I wrote was good.
As Dan McKinley puts it very well, the best way for this code to make things easy for other people is to be understandable at first glance. Smart and clever code doesn't meet this standard. Boring code does.
Boring code means code that meets long-established standards. It's boring because those standards have been known for a long time and you're smart! You can do better! Yes, you can, but no, you shouldn't. Because the next person modifying your code won't have a clue about your smart idea of the day.
In the same way, when choosing a library to answer a need you have, before jumping into the latest shiny bandwagon, ask yourself if the old and rock-stable lib everyone knows can do the job. If it can, there is probably no better choice. If and when it fails, you're more likely to have at least a few people onboard that know about that failure. When you push it to the limits, you also have experienced people that can better predict what will happen.
The only exception to this rule is areas in which you innovate, and there should be very few of them. You can't innovate on every front. Because innovation is draining your resources: it is longer to setup, harder to pickup for newcomers, harder to fine tune, more prone to bugs which are harder to debug. Just because it's new and no one has any experience with it. So choose those areas very carefully.
This is where the GTD (Get Things Done) should kick in. Use rock-solid and proven libs. Use rock-solid and proven patterns. You will be more likely to build a rock-solid platform that works without a glitch. And it will be faster and less expensive to build.
User-Agent detection in Java
java-user-agent-detection is a small lib that gives back information when given a user-agent string. It is fast (under 0.1ms) and optimized. Where you need to go from there:
If you want to leave feedback, the comments space below is a good place.
Target your CSS fonts on different platforms

Continuing on my journey to find the proper set of fonts for my website, I was a little surprised to see the way the different vendors handle native fonts in CSS. In this realm, there are three players that handle both the OS and the browser: Apple (Safari on Mac OS and iOS), Microsoft (IE on Windows) and Google (Chrome and their default browser on Android). Their handling of the native fonts is — of course — different. Let's see the different approaches.
Let's start out with the simplest one: Android. There is one font, Roboto. You can target it with the following values: sans-serif, sans-serif-light and sans-serif-condensed for the different variants. There are a few aliases such as Arial (alias to sans-serif) or Georgia (alias to serif) but if you want to target Android you should add the serif-liked syntax for better support. Then you can use font-weight and font-style to target different weight and the italic version. However, you cannot target the sans-serif-light or sans-serif-condensed with CSS attributes. You have to select them with the font-family selector.
So, to target a narrow font, you have to use sans-serif-condensed you cannot use the font-stretch:condensed property. Less options is not good. One font is not good. This is not very rich.
Notes:
- This holds true for both Chrome and the abomination installed by default on Android.
- I haven't tested anything on Chrome OS. Common sense from a vendor perspective would say that it should be similar to Android. Common sense from a product placement perspective dictates that I find it doubtful that a desktop OS would ship with so little fonts installed. All bets are open.
Microsoft
IE allows also the font-stretch to be used, along with the name of the font — if at all available, which is rare. For example, you can target font-stretch:condensed;font-family:Arial or directly font-family:"Arial Narrow", both work. Unfortunately:- there are not even a handful of fonts with condensed versions
- none are installed by default, they're installed with MS Office
- no other variation than condensed can be targeted (save the Arial Black oddity which quite doesn't work as expected — see below)
- most fonts are crap anyways
font-weight and font-style work as expected but for the fact that all fonts have only two weight available. Again, Arial Black is the exception, giving one more weight to the Arial family. But if you target it with font-weight:100 (trying to get a thinner version) well, you still end up with Arial Black.
So despite its interesting support for different types of font targeting, IE falls short because of the lack of unity and the lack of nice fonts. While testing, be also aware that not all windows users have MS Office installed, so if you do try to find a machine that doesn't to test your fonts on. MS Office comes along with a bunch of fonts and not everyone has them. This is unfortunate because those are nice fonts...
Apple
Safari doesn't support the font-stretch CSS property so far. To target a narrow/condensed font, you have to target it with its family name. The surprise on both iOS and MacOS is that you can target all variations of most fonts by their family name. Italic, light, black, bold, condensed, every variation has a family name you can target right in the font-family CSS attribute. Now, apart from the stretch, you can also target those with font-weight and font-style. For example, if you specify font-weight:600;font-family:Helvetica-Light, you'll get the regular Helvetica (the bold version of the thin font). With font-weight:700 you'll get the bold version. This is the best of both world, really. Whenever Apple starts supporting font-stretch, Safari will be the sweet spot for font selection. But as it is, it's already the best.
Moreover, Apple's (modern) fonts are declined in a variety of styles (like 5 different thickness; light, thin, regular, medium and bold) allowing better control, and they are pretty nice. So — somewhat unsurprisingly — most sites having paid attention to their fonts and relying on native font stacks will be rendered best on Apple devices.
Mixed platforms
For Firefox, well, things look very much like Chrome. It also depends on the OS. For example, trying to target Arial Narrow on Windows has to be done with font-stretch:condensed;font-family:Arial, but on Linux for example, you have to use font-family:"Arial Narrow". font-stretch:condensed; doesn't do anything on Linux.
How to test?
Testing, as always, is the right thing to do. I've set up a small page that list the fonts available on your browser. You can access this page from an iOS, Android, MacOS and Windows machine to see the fonts available. Then you can build your font-family stack with reasonable confidence. If you don't have all of those machines available, hop on to saucelabs.com to access some of those machines for free. Test the fonts on your browser
All in all, I have found that the worst platform to find fonts for is Windows. But in every case, I've found fonts that I liked for every system without much work. @font-face is not yet something I will consider for any of my websites.
Chrome and Arial Narrow
As you discovered with my previous entry, I was looking for nice condensed web fonts (read: native) for my headings. Well, I found plenty for everyone but for Chrome on Windows. Chrome issue is troublesome for me because this combination represent 30% of my traffic right now, by far outweighing other combinations of browser/OS.
How come I couldn't do it? I could do it with IE, Firefox on all platforms and Safari on all its platforms. Even Chrome on non-Windows platforms. It turns out that Chrome does not support the font-stretch: condensed CSS attribute. On other platforms, there are fonts that are condensed and can be targeted by using their name, but alas, Arial Narrow is not a font you can target with Chrome (nor with Firefox), even though IE can target it. Note that Franklin Gothic is in the same situation.
It's the first time Chrome is lagging in terms of features behind IE and Firefox (at least on something I use).
Let's hope Google addresses this problem as Arial Narrow is pretty much everywhere. And it's a pretty nice font, even though Helvetica people have probably left my website by now.
Edit on October 16: It is an issue with Chrome 37. So hopefully it'll get patched soon.
Edit on October 21: Chrome 38 is out. This is fixed.
The quest for a condensed web font
I was looking to freshen up my blog's CSS. It's that time of the year. After looking here and there, I decided I wanted a condensed font for my headings. Sans Serif. This seemed like the right thing to do.
A condensed font is a font that is a little narrower than a regular font. For example: 
As you can see, the letters are stretched and narrower than the regular version of the font.
I want a web safe and native font-stack because it is much lighter than a font-face (download-wise). You now see everywhere on the web that there is no point in targeting web safe fonts, because there are too few. So just use the CSS3 @font-face and be done with it. Well, I don't agree with this. I still care about my mobile users and imposing them a 100kB payload just to view the headers in the font I chose is not something I think is reasonable. Plus, I like the idea that my website looks a little different on every device. Hopefully it even matches the UI of the device since its using one of the device's font. I mean, using the Ubuntu font on an Ubuntu system is more likely to trigger a familiar feeling to the reader. This font is displayed in quite a few places in the OS such as the splash screen or the menus. And it seems fun.
Of course, I want my font-stack to be cross-browser. So I looked for default fonts on all my target systems. Fortunately, in my home there are plenty of different devices: iOS, Android, Windows, MacOSX and Ubuntu (Linux). This is my target right there.
The Quest
On Ubuntu, there is a nice font pre-installed called Ubuntu, and there is a condensed variation. In bold it looks fine. I also found a Liberation Sans which also has a condensed version (called Narrow). There's a better chance of having these fonts on non-Ubuntu Linux boxes. Since I couldn't find any resource on the web telling me which fonts are preinstalled on an Ubuntu system, I made it with the fonts installed on mine. Also, testing with saucelabs.com I found that their bare Linux install has Liberation Sans installed. I'll call it a day.
Then I went to iOS, where a very nice website lists all the fonts on all the versions of iOS: iosfonts.com (best viewed on an iOS device). I found two fonts that I liked in there: AvenirNext (since iOS6) and Futura (since iOS3). So there I am, iOS is now covered. The extra bonus is that for old devices I will fallback to Futura and all iOS devices can install iOS3, so I've pretty much covered 100% of iOS devices. Sweet.
Then I went to Android, where there is a new font called Roboto (as you can see there). This is unfortunately only true for recent Android devices (how recent I don't know), but it seems to me that there was no condensed font installed before that point. Too bad. There is also something peculiar about Android font families: You cannot target font-family: Roboto. This would be too simple I guess. You instead have to target a generic condensed font: font-family: sans-serif-condensed. Oh well, after all what I'm looking for is a sans serif condensed font and if/when other browsers on other platforms start picking up this peculiar syntax, well, it'll give me what I want. I guess. I hope.
I went quickly to my wife's MacBookAir, just long enough to make sure that one of my iOS fonts was installed on her Mac: Futura. They also make available a list of fonts for their OS: ht1642. The wikipedia page is much more helpful in that it has images of what the fonts look like. So I found Helvetica Neue which has a nice CondensedBold version. There I was. Done for MacOSX.
Then I went to Windows, my least favorite platform but let's face it: The one used by the vast majority of my users. I was firmly decided to get it done quickly. More than 90% of my users come from Windows 7 or 8, so I went to the Win7 fonts page. And there is the real disappointment: no condensed or narrow fonts. The narrowest font I could find is Trebuchet MS, the font I was already using for my headings. Disappointed. Very much so. So I thought that most users having Windows have Microsoft Office. I then stumbled on this page: Fonts supplied with Office 2010. There I got plenty of interesting fonts. Unfortunately, I tested this on my son's Windows 8 laptop with Office 2013, but most of the fonts listed weren't even installed. Too bad.
Then, wandering on the fringes of the interwebs, I stumbled on cssfontstack.com where I discovered a few things:
- There is a font called Arial Narrow. It works on my ubuntu even though it's not even on the installed fonts list!! Let me try that on windows... Well, things are complicated. On IE, you can target it fine either by putting Arial Narrow or by targeting Arial and specifying font-stretch: condensed. Firefox only goes with the font-stretch: condensed and Arial. Chrome as well (doesn't work on Chrome 37 though). So I'll put it with both forms as a fallback.
- Franklin Gothic Demi Cond seems to work on Windows and looks a lot nicer than Arial Narrow. Firefox and Chrome let me use the font-stretch: condensed modifier which does the job on Franklin Gothic. With IE, it works both ways. Unfortunately, I've found a few systems with Arial Narrow which don't have Franklin Gothic Demi Cond, so I cannot target it for Firefox/Chrome or else Firefox will just display Franklin Gothic, not the condensed version on those systems.
- Both these fonts are installed with Office, none are on a bare Windows install. Furthermore, to target Arial Narrow for Firefox and Chrome, you need to target Arial with a font-stretch: condensed. Hence, whether Arial Narrow is installed or not, Arial will be targeted and your font stack stops right there, because this is such an ubiquitous font. Since most Windows users have MS Office, I will still try to target it. And the rest of them will see Arial.
The Results
Here are my results so far:
Since most of the fonts I found do please me, I listed them in no particular order, except for
- My old fonts are at the last position as a last resort fallback.
- Android's declaration seems a little too generic for me, so I put is just before the fallback fonts in case some future version of browsers start interpreting it giving me unexpected results.
Final thoughts
Finally, I've got a few surprises in my quest.- iOS and MacOS are much more polished environments than the rest and finding nice fonts was just plain trivial. There are lots of documentation and examples, and devices follow them nicely.
- I thought a modern OS like Android would be more loaded with fonts and would have a better documentation.
- Ubuntu is an undocumented pile of heterogeneous stuff. Linux. No surprises there.
- I did not expect Windows to fare particularly well in here, but I certainly didn't expect it to fare that bad! Not only is the documentation just plain fuzzy and wrong, but the font choice is the worst of all OSes. To put it bluntly, it doesn't have a narrow font, not even in Windows 8. And to think this is the major desktop OS by far... I'm not wondering why MacOS shares are increasing.
And, as expected, no need for a @font-face declaration and a 70k download just to get a font I like. Most Windows users have Office installed (I hope) so this isn't a really big issue. Plus, Arial isn't that bad as a fallback. My font stack works well enough in all platform I've tested so far. That's more than enough for me.
At last, check out flippingtypical.com. It will list all the fonts your browser knows about with a nice preview. Very helpful.
The Demo Area
Here are all the fonts selected. You will see of course only the ones you have installed on your system. This is more of a test area for me than for you, but I threw it there so that you can see it. Note: I built a little tool to help you detect all the fonts you can target. Test the fonts on your browser- No style: All examples looking like this below means they don't exist on your system.
This is the test area - iOS6: Avenir Next Condensed Bold
This is the test area - iOS3: Futura Condensed Extra Bold
This is the test area - MacOSX: Helvetica Neue Condensed Bold
This is the test area - Ubuntu: Ubuntu Condensed
This is the test area - Ubuntu: Liberation Sans Narrow
This is the test area - Windows: Franklin Gothic
This is the test area - Android: Generic Sans Condensed
This is the test area - Fallback: Arial Narrow
This is the test area - Fallback: Trebuchet MS
This is the test area - Fallback: Lucida Grande
This is the test area - Fallback: Tahoma
This is the test area - Fallback: Verdana
This is the test area - Fallback: sans-serif (This is the last instruction - I want a sans serif font if nothing else is available)
This is the test area
Reeder and its companion apps: Readability vs Pocket vs Instapaper

Reeder has always been my favorite app for reading my multiple RSS feeds. Simple and elegant, it allows preloading of all your feeds so that you can read them in the subway for example.
RSS feeds are usually short summaries of blog entries, and almost all major news website has some to help follow their news stream. While some sites deliver the entire content of their articles to their RSS feeds, most only send a shortened version. Users that want to read the full story click on the link and get to their website. Of course, only if you're reading it online, which is not always my case. Also, if the article is long, you may want to save it for later. Keeping a tab open in your browser is not a great way to do that. Also, an RSS reader is a poor place to keep something for long. You usually consume what's in there pretty quickly. The flow is constant and uninterrupted.
So, for articles I want to read whole, I'm sending my content to one of three apps: Instapaper, Readability or Pocket (formerly known as "Read It Later"). All three apps are made for viewing curated web pages offline. They keep a "reading list" of all the stuff you sent to them, so it is convenient to come back later to these apps and read your stuff.
They also "curate" the web page you send them in order to remove ads, menus, headers and such. this mostly work for all three apps.
So, which one is the best? Well, this is all a matter of perspective and preference. Here are mine:
 Readability
Readability
By far, the most elegant of all three apps. I do have a few grudges against it:
- One can only read by scrolling and not by paging. Unfortunately I prefer paging by far. Just like I prefer paging when I read a novel in iBooks, I prefer paging when reading any long piece of written content.
- You can only choose between three fonts. There are plenty of fonts installed on iOS, why not propose them?
- The choice of font-size is... Well... not fine grained by any means. There are 5 predefined sizes. Of course, the size I would like is between two of the sizes proposed.
- You can only read in portrait mode, not in landscape mode. I like landscape because it shows me longer lines.
- Clicking on a link jumps straight to Safari. Isn't (one of) the purpose of this app to be able to read offline? Not practical at all.
- As many images are also links, it is more often then not impossible to zoom in on an image. The click will jump to Safari to open the link. Useless offline.
- An inline video in the article does not show up in the curated article. You don't even have a hint that you're missing something.
- The reading list gives you the number of minutes it'll take to read each entry. This give you a pretty good sense of how long the entry is.
- Best UI of the lot, very homogeneous and smooth. This is important.
- for example, when you increase font size, it applies to the body and the title of the article. This is the only app doing that.
- it is consistently downloading all images of all articles.
 Pocket
Pocket
The bad parts:
- Pocket has a presentation of your reading list that bewilders me. The title is written on the left and an image is displayed on the right hand side. This makes it looks just plain weird as sometimes the images are ugly and some articles don't even have one. And all entries have different height in the list making difficult to differentiate them sometimes.
- On the reading side, the page-by-page mode is a bit hit and miss. To activate it you have to swipe from the right to the left, but this gesture is often confused with just plain scrolling. When going landscape, the page-by-page mode goes off and you have to activate it again.
- The page-by-page mode has also a disturbing quirk: when you tap in the middle of the screen, it shows the header and menu bar at the bottom, which is customary. But in Pocket's case, these bar overlap the two last lines of the screen which then disappear. Thus, if you go to the next page, you are missing out on 2 lines of text (not drawn) for each page. When you tap again to make them disappear, the hidden text doesn't come back. You have to go to the next page and then go back. This is disturbing.
- In page-by-page mode, you have no idea of your progression in the article you're reading. No scrollbar, no progress bar, nothing.
- There are only two fonts available. Still better than one, but come on! This app is dedicated to reading, let us choose fonts!
- Playing with font size doesn't affect the title of the article. You can end up with a title smaller than the body of the article. Not very elegant.
- I also have images that won't get downloaded. On some blogs/sites it is even almost always the case. There's just nothing in their place... you don't even know you're missing something.
- Clicking on an image opens it up and you can zoom in.
- When you have a link in an article, Pocket will propose to open it as if it was another item in your reading list. So you don't have to quit the app to read it. But it doesn't get saved in your reading list. Of course also only works if you are online, defeating the purpose of the app. Couldn't I "Read It Later"? And to think the app was once named exactly like that...
- You can choose your font size point by point.
- An inline video in the article actually show up in the curated article. Of course, you cannot read it offline, and that one is understandable.
All in all, this is the less elegant app of the three, but it gets the job done. And it handles videos - it is the only one.
 Instapaper
Instapaper
Here are my grudges:
- The reading list is written in a tiny font and the excerpt in an even tinier font. And there is nothing you can do about it.
- On the reading side, the page-by-page is a bit needy. If you go from landscape to portrait (or the other way) you have to quit your article and open it again for it to work, otherwise it's just plain clunky.
- The page-by-page view is a bit buggy and below images there is sometimes a chunk of text outside the screen that you can't read. It doesn't happen very often though... Also, images are scaled to take the full width of the screen. If the rescaled image is higher than the screen, it is cropped. Not much of a problem when reading in portrait mode, pretty ugly when reading in landscape mode. Fortunately, you can click on an image to see it full screen and zoom inside it, so it is just impractical.
- Playing with font size doesn't affect the title of the article. You can end up with a title smaller than the body of the article. Not very elegant.
- I've also had images that would not be downloaded inside articles. It is pretty much consistent and no matter how many times I try to redownload the article, they're always missing. These are the same images missing from Pocket. Readability displays them fine. I couldn't figure out what makes these images not work in those apps. The good thing is that Instapaper displays the ALT/TITLE property instead (usually, the tooltip), so you know something is missing.
- An inline video in the article does not show up in the curated article.
- Clicking on an image opens it up and you can zoom in.
- In your reading list, you have a sense of the length of each article and this is a definitive plus.
- You can choose among a 14 fonts (why not all the fonts installed on the device? - this is a mystery)
- Clicking on a link gives you the option of opening the target in Safari or adding it to your reading list. If you're offline, well, it'll get added later. THIS is the proper way to handle links.
- The reading view is elegant - just like the other apps - and there is a progress bar at the bottom. This is cool.
- You can choose your font size point by point.
- You can choose your margins and line spacing.
- There is a link at the end of all articles to report a problem in an article such as a missing image for example.
- The page-by-page navigation is the best of all three apps, despite it bugs and quirks. For example, it allows you to tap on the right of the screen to go to the next page, instead of swiping which is more tedious after a while when holding the phone one handed.
Wrap up
All in all, those three apps get the job of reading articles offline done. They also curate the webpages displayed to remove the chrome and other useless stuff. This works mostly for all three of the apps. I've had a few glitches here and there on all three apps.Except Instapaper, the apps are free, so please indulge yourself and give them a shot.
For me though, Readability shines by its elegance and design, and also because it is the only app that works... Indeed, most of the grudges I hold against both other apps are a long list of bugs. Instapaper shines for my by its functionality. So far I'm using Instapaper and sometimes Readability to read stuff with images. If I didn't need page-by-page reading, I'd be a Readability-only guy.
I'll try to update this blog entry as the apps get updated. If you see anything I should add or remove, please let me know in the comments.
Changelog
October 10, 2014: Both Readability and Pocket were updated yesterday. Now, all three of the apps are compatible with the big new iPhones (6 and 6Plus) and compatible with iOS8 sharing, meaning you can send them pages from any app. None of the issues I mentioned in my article were addressed.
This article was last updated on November 3, 2014
Google is reading your email
There are two things here that trouble me.
The first one is that I do sometimes forward a received mail without thoroughly looking through the attachments. Granted, I usually know the sender and the likelihood that some child porn found its way in there is actually very remote. But still. I expect my mail to be shared with the recipient and no one else...
Now, the first concern is a little theoretical. I'm quite certain that Google searching for child porn in gmail boxes is not really a threat to me. But once the box is opened, who knows where it'll stop? Will they be searching for terrorists? Political opponents? Will searching for "homemade bomb" in gmail be reported to the police? Where does it stops, really?
The answer is of course: we don't know. And that worries me.
For now, I'm sticking with gmail because I don't have time to switch to something else. But I'm already thinking about leaving, and I will at some point.
iTunes Match vs. Google Play Music on the iPhone
Okay, so we already had a look at both services on the desktop. It's now time to get to the iPhone for a mobile app comparison. Why the iPhone? Because on Android, you cannot use iTunes Match. It's that simple.
On the Apple's front, the default music app is doing all the heavy lifting. In the settings you need to fill in your iTunes Match credentials and activate iTunes Match. Being the built-in app, it enjoys an in depth integration with the phone. For example, any music in your default music app can become a ringtone or can wake you up. You can also search your music from the home screen. It's an unfair advantage (I don't think Google could do it even if they wanted to), i'll grant you that, but it's there. The app is otherwise pretty easy and nicely done. Here, again, you can choose to stream or download songs and/or albums. They'll download in the background and if anything fails (because you suddenly go offline for example) it'll pop you a dialog so that you know. Same as in the desktop app, you can choose to view only your local collection or to see the whole iTunes Match library. The songs can be controlled through the lock screen, the headphones and while playing, your lock screen shows the album cover art and the song name, album, artist etc. It's pretty neat and works well.
One thing that annoys me is that whenever you recycle the app (restarting the phone for example) the playlist is lost. iTunes fares better on the desktop on that front. That said, whenever you launch the app it will get back to where you were, most often on the album you last listened to.
On Google's front, the app is called "Google Play Music" and is free. Once installed, you enter your Google credentials and all your music shows up. From there, you can download the music you want to listen to offline. But only albums, not individual songs. And if you leave the App (of turn off your phone) the download stops and doesn't resume automatically whenever you turn it on again. That makes the process of downloading songs a little hit and miss or painful as you have to keep the phone turned on and the app running until it finishes.
As in the default music app, you can search artists/tracks/albums but for some reason, it doesn't work. And it's not as if it kinda worked, no, on most searches I get nothing even though I know I have an album of that name. I can only think it is a bug and will be fixed, but I could not avoid mentioning it.
Another drawback of Google's music app is that it does not remember your playlist, just like the website and the default music app. So you're listening to an album then do other stuff on your phone. When you launch the app again, if it has been recycled it will show up your home screen and there is no way to resume your album - that is, unless you know which album and which track you were listening to. Pretty painful for me.
There is also the artist art, just like on the website, which is a little maddening when many artists don't have any picture and some others bewildering things in there.
One note about some annoying thing. When I tried to update tags in already-imported MP3 files, well, the files would not update as we've seen in the previous article. However, I quickly ended up with albums that showed up two or three times, as well as albums where each song would appear twice. Duplicated tracks also showed up on the website, but duplicated albums only appeared on the iOS app. And from there, the only solution I found to fix the issue was to uninstall and reinstall the app. Quite painful.
Other than that, the app works fine and my music plays just fine as well. The controls also works from the lock screen and headphones, and the album art is also displayed on the lock screen with all other infos.
The wrap up
In Apple's favor:- Better integration to iOS (unfair advantage, but advantage nonetheless)
- Download are much more likely to actually get downloaded.
- Ability to view only the music you have offline.
There's really nothing where the play music app surpasses Apple's.
And the winner is Apple, just like on the desktop. That said, just like on the desktop, both apps actually work and are solid music players, but Google's version is notably lacking some pretty useful features and some maturity. I'm just back from holidays in a place where I didn't have free cellular access, and to sum it up, I didn't listen to music at all since most of my albums were not downloaded and I had no simple way of finding out which ones were anyways. Google's music player is, in this regard, barely useable.